Memory
In the last issue I have addressed three “stepping stones” laid on the quest to Artificial Intelligence. Neural networks as the centrepiece of connectionism have been proved as powerful tools to solve cognition problems in vision and languages. I also approached intelligence before language, why it is equally important and how we attempt to solve it with reinforcement learning. There are deeper processes undergoing, more subtle, the underwater iceberg, background running beneath of our consciousness and sub-consciousness, which means a lot harder to identify, scope, and model. Among those includes memory.
The Classics
Memory is an indispensable part for any computer: internal (short-term) memory (RAM) stores immediate calculations and information; external (long-term) memory (for example hard drives, compact discs, USB sticks) store persistent data. Short-term memory stores temporary data required by processes and to minimize read/write latency; outdated information is overwritten by newer content. Less demanding content is stored on external storage devices, guaranteeing retrievability in the future. This is the most straightforward understanding of what computer memory is. If a computer is smart which means it programs itself, how different memory would be designed apart from that of Von-Neumann architecture?
From the perspective of psychology Atkinson and Shiffrin proposed a multi-store model in which memory types are classified with respect to their temporal duration, to some extent, quite similar to computer’s memory layout. The psychological model defines the three: i) ultra short-term memory is linked with sensory data for periods of less than one second, ii) short-term memory refers to the persistence of information for up to 30 seconds; information that needs to be stored for a longer time is transferred from the ultra-short level to here though not every content could be saved but with a limited capacity; iii) long-term memory stores information over a very long period of time, possibly a whole lifetime.
While this taxonomy is perceptually based on how far back in the past a memory could be retrieved, it seems not being justified with biological evidences that human’s memory is organized such a way. There are different models of memory as you may find from the Wikipedia links given for each memory type on the above, we however all know that they are unlikely reflect the true but unknown remembering processes of human being. The quest of finding a proper working model of memory for the sake of AI, henceforth, is fairly elusive.
Understanding the role of memory, and how it is organized in the mind is difficult, as much difficult as explaining the cause of Alzheimer’s disease. Getting to know a bout a disease helps us understand better the way to AI ? As alienate as it may sound, studying diseases indeed opens rare opportunities to understand more about how memory is organized.
On early symptoms,
Alzheimer’s disease does not affect all memory capacities equally. Older memories of the person’s life (episodic memory), facts learned (semantic memory), and implicit memory (the memory of the body on how to do things, such as using a fork to eat or how to drink from a glass) are affected to a lesser degree than new facts or memories.
It could be that longer-term memories are reinforced by lots more neuronal connections so that they are not easily to be messed up. Were that connection is indispensable to memory?
This could be scientifically wrong, but thinking of memory as a library is intuitive: memory as a book, Dewey indexed and being placed on bookshelves, ready for retrieving at any time. What if the book is placed at a wrong place ? Then it certainly could not be found (well, quick enough) unless bookshelves are thoroughly searched. To this end a trace linked to a memory is as important as the memory itself. Given two objects of memory and its trace for remembering to work, what should decide a neuron serves as trace and others as memory storage? Losing memory then traces lead to nowhere, losing traces then memory is dangled. How could one tell the two-sides-of-a-coin exists separably ?
The book-library example is a good illustration of organizing (semantic) memory using symbolic approaches. The modelling of memory relies on the locality of each remembered event and the hierarchy of knowledge.

We also know from my previous post that efforts have been made to build huge knowledge graphs. It is easy to see that this approach requires massive amounts of time and efforts to embrace unlimited semantic concepts in reality, and there are strong signs showing that it will never end.
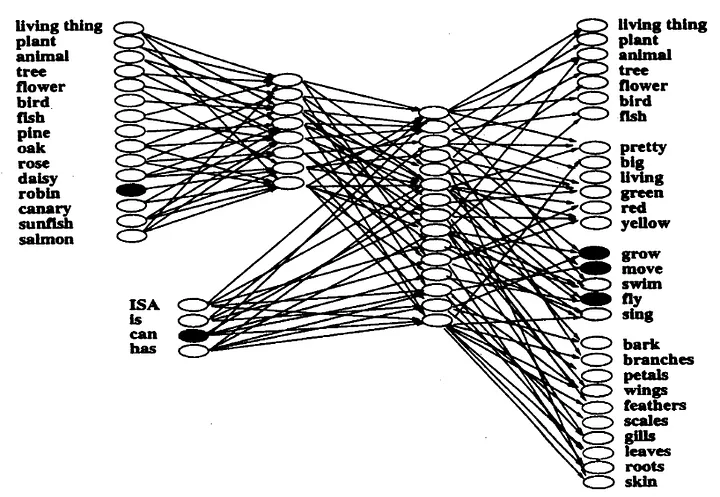
Connectionists propose an alternative approach to memory representation where relationships and attributes between information units are associated (or “learned”) rather than being engineered. In Rumelhart’s work, an auto-association network was designed to couple objects with their attributes via using a learning algorithm called back-propagation whose principle is tuning weights of neural connections.
For connections are many and specialization of connections and weights for each association are coincidental (in fact it depends on initial weights which are randomized too), memory patterns are no longer local but distributed across the network. What does memory trace mean under distributed setting? The trace itself is the memory. Memory and Learning
The principle of memory as distributed associations means that there is no individual traces but memory exists as causal links between stimuli. Memory is stored when the excitation of a given sensory input strengthens weight connections perceptrons, or the thickening of synapses connecting neighbouring neurons in the case of biological neurons. In neuroscience this principle is known as synaptic plasticity upon which Hebbian learning theory was built:
Neurons that fire together, wire together. Neurons that fire out of sync, fail to link.
This motto is generalized from the phenomenon of Long-Term Potentiation (LTP), defined as
the increase in synaptic response following potentiating pulses of electrical stimuli that sustains at a level above the baseline response for hours or longer. LTP involves interactions between postsynaptic neurons and the specific pre-synaptic inputs that form a synaptic association, and is specific to the stimulated pathway of synaptic transmission.
The literature of Hebbian learning and neuroscience is vast nevertheless some key points relevant to machine learning could be highlighted as follows:
- Neighbouring neurons link together via causal firing. Long term links could be formed as the repetition of similar stimuli. This may explain different “lifetimes” of short-term memory versus long-term ones. When one learns something many times, it tends to stay in one’s mind longer.
- Hebbian learning works in an unsupervised way, because there is no signals controlling or guiding local associations between neurons. Synaptic strength relies on the co-excitation of neurons which in turn depends on sensory inputs.
- Weight updates — by Hebbian rules — are local. Biological neurons can access information only from its locality. Backprop is incompatible with Hebbian learning because backprop may require information from non-local neurons in the backward pass.
Hebbian learning received much attention and was applied in Hopfield memory network and Boltzman machine. These models are essentially recurrent neural networks where outputs of neurons are fed as other neurons’ inputs. Their learning processes henceforth evolve over time (thus the “recurrent” term) until an equilibrium state between neurons is obtained. The idea was in fact built upon Ising model, a physical modelling of phase transition of particles in thermodynamics. As a rough analogy, an equilibrium state in learning can be compared with ferromagnetism. Iron is magnetic; its the electrons could be made to spin in the same direction using only local forces therefore once it is magnetized it stays magnetized for a long time.
It worths investigating Hopfield network a bit deeper in its architecture to see how memory is implemented as mutual associations.
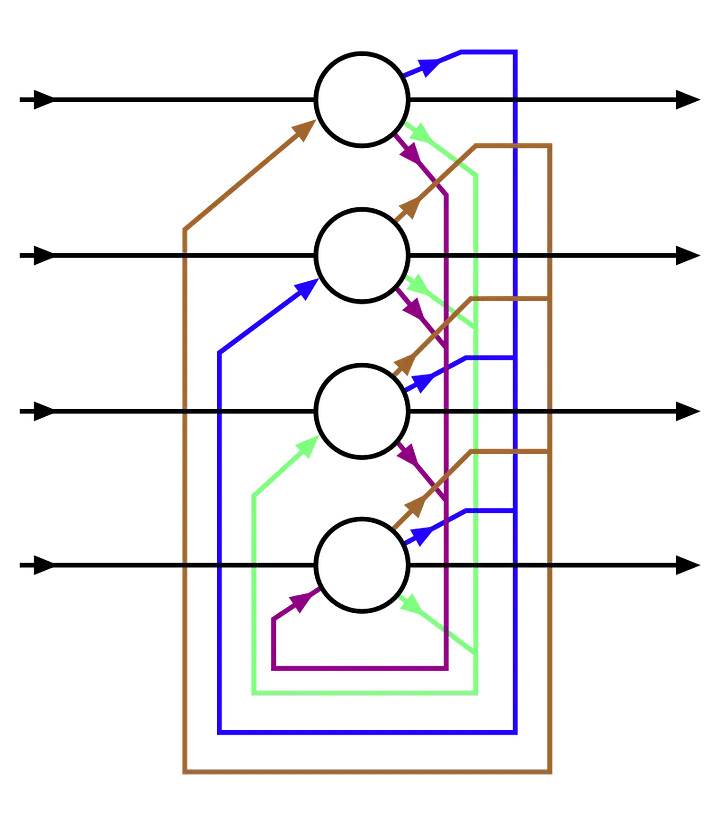

For the content of every neuron is affected by all other neurons, patterns (called memory) in a Hopfield network are distributively stored among different neurons; in other word the joint-excitation of multiple neurons is the basis of distributed memory. Under this regime memory never exists out of its context.
Memorization vs Generalization
It is no mystery that ultra-short and short-term memories are indispensable for us to complete both trivial and non-trivial tasks, in order for ones to remember immediate steps required by those tasks. Temporary memory is supposed to be erased after tasks are done. On the contrary long-term memory has deeper and broader impacts over the course of human learning. What is their purpose if not to be recalled and to remind Present? Memory could be about either a lesson learned when in pain or an experience of joyfulness. The more trenched a memory is, the stronger we feel when we remember it, sometimes it feels very real as if it were not from some distant past.
In machine learning, the simplest way to implement long-term memory is for models to keep (a part of) training data and use them as medium for inference. They are called non-parametric methods. The term “non-parametric” means that algorithm complexity is not relied on the parametrization of data modelling, but data cardinality; the complexity grows as the number of training examples increases.
The most naive learning algorithm is k-Nearest Neighbors (kNN) which keeps every training data points as its assets. Smarter large margin algorithms such as Support Vector Machines (SVM) only retains an optimal subset of data points; highly confident data points are less useful in establishing decision boundaries and therefore discarded. Generalization in learning, viewing it from the margin-based methods, is to drop what is not worthy remembering, and to remember only memorable information.
Remembering and Forgetting
Connectionist networks — as well as other parametric techniques — in the other hand do not keep a record of the data; the error-correcting back-prop tunes connection weights with respect to amounts of errors those weights are responsible of making so that to minimize errors to be made in the future. Knowledge from data is “distilled” into the weight space of neural nets. In online learning settings, where data distribution may adjust over time, neural networks trained by back-prop are subjected to the phenomenon of catastrophic interference (or forgetting) where newer weight updates override learned weights in the past. In other word, as the network “learns” new data it will soon forget older knowledge.
Forgetting actually is not bad. We as human forget a majority of information that we read, watched, and learned. Forgetting is essential as much as remembering during a course of learning. In statistical learning, a learning algorithm generalizes over the training data in order to predict well on unseen data. Generalization is to go beyond memorizing data: to forget specificities of individual data points and common patterns to be emerged. A research from psychology and neuroscience supports this view, regarding remembering (persistence) and forgetting (transience) are both vital in playing intertwined roles enabling flexible and intelligent decision making in a dynamic and noisy environment. Don’t be panic if you forget about something, it is not just about making rooms for new memory.
So what about catastrophic interference? It happens when back-prop algorithm is used to update a pre-learned neural net. Every connection weight is subjected to changes because memory is distributively stored over multiple neurons. If weights learned from old training data cause much of prediction errors then they are to be adjusted accordingly with new training data. Interference happens at this point given that in general new data have different distributions from the old ones’. Vanilla feed-forward neural networks have no mechanism to tackle this problem.
To cope with (data) covariate shift scenarios, learning algorithms need to know what to be kept whilst others can be discarded. In other word, for continual learning being possible, solutions are about how to retain necessary old memory whilst not limiting the capacity of learning new concepts. Ideas to extend memory capacity for neural networks are many: adding more neurons and layers, sparsifying connections, compressing memory, and so on. However this is not the only arena of connectionism.
Gaussian Process (GP) — a family of stochastic processes that models data as being generated from a mixture of Gaussian functions — was used is found to help filtering memorable past from the plethora of data. Given the weight space of a pre-trained neural net, this work proposed a way to convert the network into Gaussian processes; and because GPs are great tools to quantify data uncertainty and prediction confidences, they are used to retrieve a subset of memorable past — which are most of the time hard examples needed to pay attention to — the ones that will be kept in future learning rounds so that the past is replayed again.
Storing “raw memory” this way where representation of memory is the data itself has its drawbacks. It is less efficient to query relevant memory because it merely store discrete data points. Successive learning most of the time has to re-run all over old and new data. Smarter memory layout is necessary.
External Memory
The classical Von Neumann computer architecture uses external memory to store data which is occasionally needed. Access speed is slower than internal memory (RAM and GPU registers) however massive chunks of memory could be persisted on disks without fearing of a power cut. Files and directories are simply indexed by FAT tables; the PC does not need to know where the content is because we human as users remember the content that we want to save and access. Building an AI system with memory, then AI must knows by itself how and where to look for the content it needs. It turns out that a memory access processor — a retriever and an indexer, depending on reading or writing memory — has to be intelligent.
Differentiable neural computers (DNC) (alternative link to avoid Nature’s paywall) is such a memory-augmented neural network. It was motivated by neural nets having the ability to “think slow” — deliberate or reason using knowledge (a.k.a memory). The controller of DNC can either write new information to where and when or read from multiple locations in memory based on matched contents between the memory and the query. Just like kids playing Lego, a complex structure requires assembling several sub-modules separately and then combining them the right order; short-term memory is essential to be able switch between steps.
A rather interesting phenomenon in human nowadays — examples of using external memory — is Internet and search engines. Given meticulously and massively engineered search technologies like Google and Bing, we delegate, without hassle, remembering tasks to search engines. For example I can remember myself the list of input arguments of a NumPy function but I rather remember the keyword to find its documentation elsewhere via Google; or I can remember myself how to fix a buggy snippet of code that I have repeatedly used over the years, however I rather search for its solution from Stack Overflow again and again, whenever I need it. Those pages are my “external memory” and my brain — or the controller — just need to remember of how to access to those knowledge. Does this make me being more dependent to Internet and technology ? Yes. Being more productive? Quite likely, but not in the sense of how fast, but how vast amount of different issues that I can deal with. Accessing to external memory may not reward you faster thinking but lots more possibilities and choices in making up your mind.
External memory will expand usecases of deep learning such as complex question-answering, proving scientific equations, predicting molecular structures for drug discovery, causal inference, generating book-length fictions. In other word external (long-term) memory is an important factor to unlock symbolic inference inside a sub-symbolic system. The remaining element yet to be discussed is short-term memory. Temporary information is forgotten soon after it is no longer needed which supports a design choice of using internal structures to store short-term memory. Internal Memory
Table of contents in deep learning textbooks are often found of classifying literature of neural networks based on data types: for scalars or general vectorial data multi-layer perceptrons is introduced; for images convolutional neural nets are the go-to; for sequential data including texts, time-series, and videos, it is recurrent architectures to us. These are called off-the-shelf tools and bearing data-centric point of view. Artificial intelligence however should prefer an intelligence-centric point of view which relate not only data science and machine learning but also psychology, neuroscience and philosophy. I often think of differentiating neural architectures by having memory or not. This perspective makes sense of machine learning techniques within a broader AI landscape.
We have discussed external (long-term) memory which was shown to be useful in slow reasoning, incorporating knowledge and rules. With networks with external memory, the controller is differentiable however it is not needed to be so for the organization of the memory. For example it could be a hashed dictionary, or a linked list. Symbolic knowledge also finds easy to be stored this way. Having internal memory is another step forward and this type of memory is tightly integrated with the neural network. In other word, it is the network, designed in a way that enables temporary data is remembered.
It has been long known that short-term memories are indispensable for human to resolve daily tasks from simple to complex. Can win a memory card game? Congratulations because your short-term memory works very well! Sequential data such as text, daily temperature data, or stock market time-series has a high level of dependencies between successive steps.
Let us take some examples of English sentences from his famous work of Claude Shannon in 1948. In this work he illustrated the idea that text sequences are not random letters but imposing statistical structure of specific languages. Comparing a sequence of Alphabet letters independently drawn:
XFOML RXKHRJFFJUJ ZLPWCFWKCYJ FFJEYVKCQSGHYD QPAAMKBZAACIBZLHJQD
versus random sampling over di-gram and tri-gram structures respectively:
ON IE ANTSOUTINYS ARE T INCTORE ST BE S DEAMY ACHIN D ILONASIVE TUCOOWE AT TEASONARE FUSO TIZIN ANDY TOBE SEACE CTISBE,
and
IN NO IST LAT WHEY CRATICT FROURE BIRS GROCID PONDENOME OF DEMONSTURES OF THE REPTAGIN IS REGOACTIONA OF CRE.
N-gram language models have been developed in linguistics and statistical learning long before deep learning started to have impacts. Longer dependencies of a word to its precedent words in a sentence — the bigger N is — the better guess for the next word to follow in order to form a meaningful sentence, and going beyond, sentences, and paragraphs. Obstacles on scaling up N is the sparsity problem: lack of data to model probability of low occurrences or training corpus have to be bigger and so do the models.
By having memory, connectionist approaches can do the job, and often doing better. The rest of the story was already mentioned in my last post about the success of neural language models. The beginning of the story, containing more insights and mysteries being explained, worths considering.
To match the above example from Shannon’s paper, I cite an example from Andrei Karpathy’s blogpost the effectiveness of recurrent networks. He built a character-level recurrent neural network learning dependencies between characters in English, in order to generate new texts. During the course of training his model, samples were generated every 100 iterations. At iteration 100 the result looks nonsense but word spacing was learned:
tyntd-iafhatawiaoihrdemot lytdws e ,tfti, astai f ogoh eoase rrranbyne ‘nhthnee e plia tklrgd t o idoe ns,smtt h ne etie h,hregtrs nigtike,aoaenns lng
At iteration 500 it learned to spell commonly used words such as “we”, “He”, “and”, etc:
we counter. He stutn co des. His stanted out one ofler that concossions and was to gearang reay Jotrets and with fre colt otf paitt thin wall. Which das stimn
And finally at iteration 2,000:
“Why do what that day,” replied Natasha, and wishing to himself the fact the princess, Princess Mary was easier, fed in had oftened him. Pierre aking his soul came to the packs and drove up his father-in-law women.
The sentence is nonsensical however limited grammatical and vocabulary structured are evolved better and better during training. How did the network model possibilities of character and word dependencies between words and sentences? The secret lies in the recurrent design with feedback connections: the output at a current stage become the input for the next stage. The loop brings past to the present and therefore imposing internal memory when reading input sequences. One of the most well-known recurrent networks is called Long Short-Term Memory (LSTM).
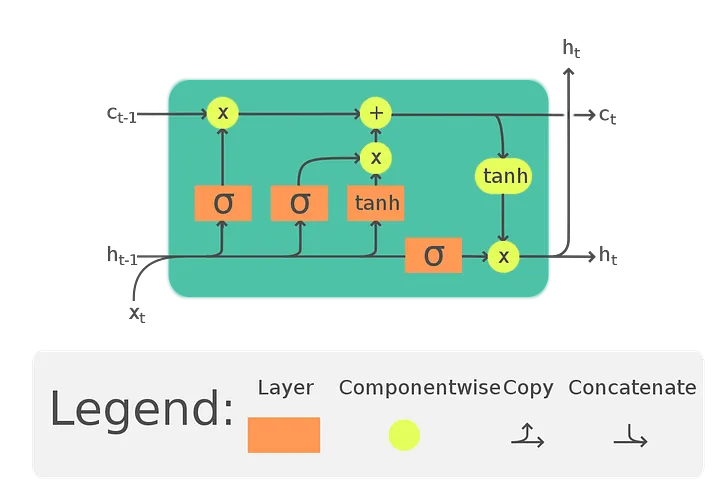
At the centre of a LSTM memory cell maintains a state registering mutable information, regulated by logic structures called gates which have three (from left to right the nodes “X”):
Forget Gate looks at both the current time-step input and output state of the previous time-step, in order to decide if some of features in the cell state (the cell state is supposed to be a vector) should be forgotten. Input Gate provides new information updates to the cell state, and by how much. Output Gate selects which feature(s) of the cell state is returned by the end of the current time-step. It works like a feature selection step.
In brief LSTM cells can — at the same time — memorize, forget, and specialize themselves to different pieces of information. After a long enough number of training epochs an equilibrium point in the weight space is achieved, leveraging memory capacity from multiple cells to harness long term dependencies in data. Walk-through steps in LSTM are explained very well here. Evidences of feature specialization was also shown in Karpathy’s blogpost where LSTM network was trained against C source codes and the resulting model has memory cells dedicated to detecting quoted texts and comments, nested if-else conditioning, end of lines, and so on.
LSTM is only a notable example of how memory is used in neural networks. Recurrent architectures in general with feedback loops can retain past information for future references. It may not be trivial to realize that many problems championed by non-recurrent architects could also be reformulated and solved by recurrent nets. Let us take a case of synthetic image generation. Images — most of the time — are best framed together with convolutional nets, largely due to their inductive bias of regular pixel lattices, facillitating sparse connections and super fast convolution. Image synthesis has been widely experimented including Convolutional Variational Auto-Encoders and Generative Adversarial Networks. In either cases synthetic images are generated within a single inference pass. Every details at different places in the image emerges at the same time. Human drawing pictures, on the contrary, is not like that. They first sketch rough figures, lines and blocks, then refine from parts to parts, from coarse to fine; every part is drew in relative to other parts in order to maintain a good visual coherency, pleasant ratios, and geometrical harmony. Such is a sequential process where successive steps are conditioned on their precedent data.
Can we serialize the image generation process in a similar way, using recurrent architecture as a way to provide memory? ImageGPT from OpenAI proposed ravelling a two-dimensional image into a one-dimensional sequence of pixels so that their Transformer models used on language can be applied onto color pixels. Given a half completed image, it was able to generate the other half with high level of visual coherency, for example this cat photo:

Besides generative modelling, memory can also be used to realize “eye gazing” over images, enabling detecting and tracking visual objects in a human’s way, i.e. not the mainstream dense sliding window approach. This recurrent model for visual attention processes inputs sequentially, attending to different locations within the images one at a time, and incrementally combines information from these fixations to build up a dynamic internal representation of the scene or environment.
Memory and Self
Given an AI algorithm with a Swiss-knife set of memory, would consciousness and selfness grow out of it? If yes then how but if not then what else would make it to happen? We may all agree that there are moments in our lives that could never been forgotten. They could be sad or happy or horrifying memories. Life-long memory is for events uniquely interwoven by layers of senses: visual and sound, physical impact and emotion, smells and tastes, etc. You may ask yourself what are the impacts those life-long memory could make, that may change your life forever ? For better or worse, recalling memories refreshs those past moments. Are they there to teach us, again and again, not to forget how we reacted in the first place? For events that are performed many times, they are less remembered the second or third times and so on.
Then if ourself is shaped by what is remembered and what is not, can computer has a sense of itself, by relying on a smart algorithm that accumulates experiences that happened to it? If intelligence could ever be possible for a machine if it has no selfness ? A self-less AI may pass A-level exams, doing well at maths and physics (have a search on QA deep learning experiments tackling maths examples and you will see), and even writing a good essay (turn out to be quite ready with foundation models — a freshly cooked terminology to name Transformer-based giant models such as GPT’s and BERTs trained on massive amount of data), but still, fail the Turing test if somebody asks questions about its own experiences in life. What would it be the roles of memory in order to make AI to pass such questions ? However if this memory collection is no different than a logfile, then it could not, not in any way, to give computers consciousness. Memory has to go beyond it.
Further readings
- John Sutton, Philosophy and Memory Traces, Cambridge University Press 1998
- James L. McClelland, Connectionist Models of Memory
- Sukhbaatar S, Szlam A, Weston J, Fergus R. End-to-end memory networks. arXiv preprint arXiv:1503.08895. 2015 Mar 31.